好程序員-千鋒教育旗下高端IT職業(yè)教育品牌
官方微信
2022-11-11
節(jié)點 namenode zkfc
什么是HA
HA: High Availability,高可用集群,指的是集群7*24小時不間斷服務(wù)。
為什么需要HA
在HDFS中,有NameNode、DataNode和SecondaryNameNode角色的分布,客戶端所有的操作都是要與NameNode交互的,同時整個集群的命名空間信息也都保存在NameNode節(jié)點。但是,現(xiàn)在的集群配置中只有一個NameNode,于是就有一個問題: 單點故障
那么,什么是單點故障呢?現(xiàn)在集群中只有一個NameNode,那么假如這個NameNode意外宕機、升級硬件等,導致NameNode不可用了,整個集群是不是也就不可用了?這就是單點故障的問題。
為了解決這樣的問題,就需要高可用集群了。
高可用的備份方式
●主從模式(冷備)
準備兩臺服務(wù)器, 準備相同的程序。 一臺服務(wù)器對外提供服務(wù), 稱為主節(jié)點(Active節(jié)點); 另外一臺服務(wù)器平時不對外提供服務(wù), 主要負責和Active節(jié)點之間進行數(shù)據(jù)的同步, 稱為備份節(jié)點(Standby節(jié)點). 當主節(jié)點出現(xiàn)故障, Standby節(jié)點可以自動提升為Active節(jié)點, 對外提供服務(wù)。 ZooKeeper實現(xiàn)的集群高可用, 采用的就是這種模式。
我作為一個班級的講師,在班級負責授課的工作。如果我有一天生病請假了,是不是咱們班級就得自習一天了?為了解決這樣的問題,教學部安排另外一個講師,每天跟著我。我上課講課,他就在旁邊聽著;我上課提問問題,他就在旁邊看著;我去吃飯,他也在旁邊跟著;我去上個廁所,他也在跟著!做為我的一個影子存在著。由于這個同時每天都會跟著我,因此我的一言一行,講了什么內(nèi)容,留了什么作業(yè),吃了什么飯,抽了幾根煙,他都知道!那么,如果有一天我生病請假了,他是不是就可以直接替代我為班級上課呢?
●雙主互備(熱備)(了解)
準備兩臺服務(wù)器, 準備相同的程序. 同時對外提供服務(wù)(此時, 這兩臺服務(wù)器彼此為對方的備份), 這樣, 當一臺節(jié)點宕機的時候, 另外一臺節(jié)點還可以繼續(xù)提供服務(wù).
小明到肯德基吃飯,找服務(wù)員點餐,這是正常的流程。但是,如果服務(wù)員只有一個,并且恰好生病了,那么小明是不是將沒有辦法正常點餐了。為了解決這個問題,肯德基雇了兩個服務(wù)員,同時提供服務(wù),這樣一個服務(wù)員出問題了,另外一個服務(wù)員依然可以提供服務(wù)。
●集群多備(了解)
基本上等同于雙主互備, 區(qū)別就在于同時對外提供服務(wù)的節(jié)點數(shù)量更多, 備份數(shù)量更多 肯德基覺得兩個服務(wù)員也不保險,有兩個同時生病的可能性,于是又多雇了幾個服務(wù)員。
高可用的實現(xiàn)
我們在這里采用的是主從模式的備份方式,也就是準備兩個NameNode,一個對外提供服務(wù),稱為Active節(jié)點;另外一個不對外提供服務(wù),只是實時的同步Active節(jié)點的數(shù)據(jù),稱為Standby的節(jié)點。
為了提供快速的故障轉(zhuǎn)移,Standby節(jié)點還必須具有集群中塊位置的最新信息。為了實現(xiàn)這一點,DataNodes被配置了兩個NameNodes的位置,并向兩者發(fā)送塊位置信息和心跳信號。也就是說,DataNode同時向兩個NameNode心跳反饋。
高可用架構(gòu)圖
ZN1ZN3ZN2ZKFAILOVERCONTROLLERZKFAILOVERCONTROLLERZKFCZKFCJN3JN1JN2NN1NN2STANDBYACTIVEDN2DN3DN1
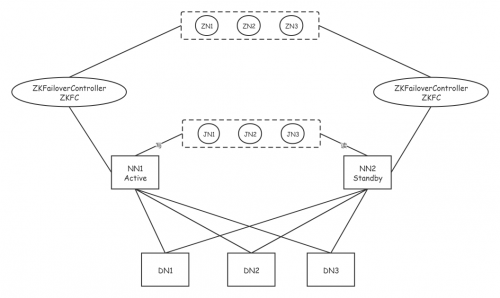
JournalNode
●JournalNode的功能
Hadoop2.x版本之后, Clouera提出了QJM/QuromJournal Manager, 這是一個基于Paxos算法實現(xiàn)的HA的實現(xiàn)方案 1. 基本的原理就是使用2N+1臺JN存儲EditLog, 每次寫入數(shù)據(jù)的時候, 有半數(shù)以上的JN返回成功的信息, 就表示本次的操作已經(jīng)同步到了JN 2. 在HA中, SecondaryNameNode這個角色已經(jīng)不存在了, 保證Standby節(jié)點的元數(shù)據(jù)信息與Active節(jié)點的元數(shù)據(jù)信息一致, 需要通過若干個JN 3. 當有任何的操作發(fā)生在Active節(jié)點上的時候, JN會記錄這些操作到半數(shù)以上的節(jié)點中. Standby節(jié)點檢測JN中的log日志文件發(fā)生了變化, 會讀取JN中的數(shù)據(jù)到自己的內(nèi)存中, 維護最新的目錄樹結(jié)構(gòu)與元數(shù)據(jù)信息 4. 當發(fā)生故障的時候, Active節(jié)點掛掉, 此時Standby節(jié)點在成為新的Active節(jié)點之前, 會將讀取到的EditLog文件在自己的內(nèi)存中進行推演, 得到最新的目錄樹結(jié)構(gòu). 此時再升為Active節(jié)點, 可以無縫的繼續(xù)對外提供服務(wù).
●防止腦裂的發(fā)生
對于HA群集的正確操作至關(guān)重要,一次只能有一個NameNode處于Active狀態(tài)。否則,名稱空間狀態(tài)將在兩者之間迅速分散,從而有數(shù)據(jù)丟失或其他不正確結(jié)果的風險。為了確保該屬性并防止所謂的“裂腦情況”,JournalNode將一次僅允許單個NameNode成為作者。在故障轉(zhuǎn)移期間,變?yōu)榛顒訝顟B(tài)的NameNode將僅承擔寫入JournalNodes的角色,這將有效地防止另一個NameNode繼續(xù)處于活動狀態(tài),從而使新的Active可以安全地進行故障轉(zhuǎn)移。 - 怎么理解腦裂? 就是Active節(jié)點處于網(wǎng)絡(luò)震蕩狀態(tài),假死狀態(tài),Standby就轉(zhuǎn)為Active。等網(wǎng)絡(luò)震蕩過后,就有兩個Active了,這就是腦裂。
●JournalNode集群正常工作的條件
- 至少3個Journalnode節(jié)點 - 運行個數(shù)建議奇數(shù)個(3,5,7等) - 滿足(n+1)/2個以上,才能正常服務(wù)。即能容忍(n-1)/2個故障。
●JournalNode的缺點
在這種模式下,即使活動節(jié)點發(fā)生故障,系統(tǒng)也不會自動觸發(fā)從活動NameNode到備用NameNode的故障轉(zhuǎn)移,必須需要人為的操作才行。要是有一個能監(jiān)視Active節(jié)點的服務(wù)功能就好了。 這個時候,我們就可以使用zookeeper集群服務(wù),來幫助我們進行自動容災了。
自動容災原理
如果想進行HA的自動故障轉(zhuǎn)移,那么需要為HDFS部署兩個新組件:ZooKeeper quorum和ZKFailoverController進程(縮寫為ZKFC)
Zookeeper quorum
Apache ZooKeeper是一項高可用性服務(wù),用于維護少量的協(xié)調(diào)數(shù)據(jù),將數(shù)據(jù)中的更改通知客戶端并監(jiān)視客戶端的故障。HDFS自動故障轉(zhuǎn)移的實現(xiàn)依賴ZooKeeper進行以下操作:
- 故障檢測 集群中的每個NameNode計算機都在ZooKeeper中維護一個持久性會話。如果計算機崩潰,則ZooKeeper會話將終止,通知另一個NameNode應觸發(fā)故障轉(zhuǎn)移。 - 活動的NameNode選舉(HA的第一次啟動) ZooKeeper提供了一種簡單的機制來專門選舉一個節(jié)點為活動的節(jié)點。如果當前活動的NameNode崩潰,則另一個節(jié)點可能會在ZooKeeper中采取特殊的排他鎖,指示它應成為下一個活動的NameNode。
ZKFC
ZKFailoverController(ZKFC)是一個新組件,它是一個ZooKeeper客戶端,它監(jiān)視和管理namenode的狀態(tài)。運行namenode的每臺機器都會運行一個ZKFC,該ZKFC負責以下內(nèi)容:
- 運行狀況監(jiān)視 ZKFC使用運行狀況檢查命令定期ping其本地NameNode。只要NameNode以健康狀態(tài)及時響應,ZKFC就會認為該節(jié)點是健康的。如果節(jié)點崩潰,凍結(jié)或以其他方式進入不正常狀態(tài),則運行狀況監(jiān)視器將其標記為不正常。 - ZooKeeper會話管理 當本地NameNode運行狀況良好時,ZKFC會在ZooKeeper中保持打開的會話。如果本地NameNode處于活動狀態(tài),則它還將持有一個特殊的“鎖定” znode。該鎖使用ZooKeeper對“臨時”節(jié)點的支持。如果會話到期,則鎖定節(jié)點將被自動刪除。 - 基于ZooKeeper的選舉 如果本地NameNode運行狀況良好,并且ZKFC看到當前沒有其他節(jié)點持有鎖znode,則它本身將嘗試獲取該鎖。如果成功,則它“贏得了選舉”,并負責運行故障轉(zhuǎn)移以使其本地NameNode處于活動狀態(tài)。故障轉(zhuǎn)移過程類似于上述的手動故障轉(zhuǎn)移:首先,如有必要,將先前的活動節(jié)點隔離,然后將本地NameNode轉(zhuǎn)換為活動狀態(tài)。
自動容災的過程描述
ZKFC(是一個進程,和NN在同一個物理節(jié)點上)有兩只手,分別拽著NN和Zookeeper。(監(jiān)控NameNode健康狀態(tài),并向Zookeeper注冊NameNode);集群一啟動,2個NN誰是Active?誰又是Standby呢? 2個ZKFC先判斷自己的NN是否健康,如果健康,2個ZKFC會向zoopkeeper集群搶著創(chuàng)建一個節(jié)點,結(jié)果就是只有1個會最終創(chuàng)建成功,從而決定active地位和standby位置。如果ZKFC1搶到了節(jié)點,ZKFC2沒有搶到,ZKFC2也會監(jiān)控watch這個節(jié)點。如果ZKFC1的Active NN異常退出,ZKFC1最先知道,就訪問ZK,ZK就會把曾經(jīng)創(chuàng)建的節(jié)點刪掉。刪除節(jié)點就是一個事件,誰監(jiān)控這個節(jié)點,就會調(diào)用callback回調(diào),ZKFC2就會把自己的地位上升到active,但在此之前要先確認ZKFC1的節(jié)點是否真的掛掉?這就引入了第三只手的概念。 ZKFC2通過ssh遠程連接NN1嘗試對方降級,判斷對方是否掛了。確認真的不健康,才會真的 上升地位之a(chǎn)ctive。所以ZKFC2的步驟是: 1.創(chuàng)建新節(jié)點。 2.第三只手把對方降級。 3.把自己升級 那如果NN都沒毛病,ZKFC掛掉了呢?Zoopkeeper有一個客戶端session機制,集群啟動之后,2個ZKFC除了監(jiān)控自己的NN,還要和Zoopkeeper建立一個tcp長連接,并各自獲取自己的session。只要一方的session失效,Zoopkeeper 就會刪除該方創(chuàng)建的節(jié)點,同時另一方創(chuàng)建節(jié)點,上升地位。


 掃碼開啟架構(gòu)師蛻變之旅 >>
掃碼開啟架構(gòu)師蛻變之旅 >>
開班時間:2021-04-12(深圳)
開班盛況開班時間:2021-05-17(北京)
開班盛況開班時間:2021-03-22(杭州)
開班盛況開班時間:2021-04-26(北京)
開班盛況開班時間:2021-05-10(北京)
開班盛況開班時間:2021-02-22(北京)
開班盛況開班時間:2021-07-12(北京)
預約報名開班時間:2020-09-21(上海)
開班盛況開班時間:2021-07-12(北京)
預約報名開班時間:2019-07-22(北京)
開班盛況
Copyright 2011-2023 北京千鋒互聯(lián)科技有限公司 .All Right
京ICP備12003911號-5
 京公網(wǎng)安備 11010802035720號
京公網(wǎng)安備 11010802035720號













